

Reasoning-KI denkt mit, statt nur zu raten. Erfahren Sie, wie Modelle planen, wo Risiken lauern (Halluzinationen!) und wie Sie KI sicher für Gesundheit & Reisen nutzen.
Transparenz
Text und Bild(er) mit KI-Unterstützung erarbeitet.
Kurz erklärt: Was bedeutet Reasoning?
Reasoning-KI löst ein Problem nicht „aus dem Bauch heraus”, sondern arbeitet es Schritt für Schritt ab. Klassische Sprachmodelle wie frühe Versionen von ChatGPT oder Gemini generieren Antworten Wort für Wort, ähnlich wie ein Mensch beim freien Sprechen. Reasoning-Modelle hingegen zerlegen komplexe Aufgaben in Zwischenschritte, prüfen Hypothesen und korrigieren Fehler intern, bevor sie eine finale Antwort liefern.
Der Vorteil: Sie können nicht nur besser nachvollziehen, wie eine Antwort zustande kommt – die Systeme eignen sich auch besser als intellektueller Sparringspartner für komplexere Denkprozesse.
Beispiel: Die Gedankenkette (Chain-of-Thought)
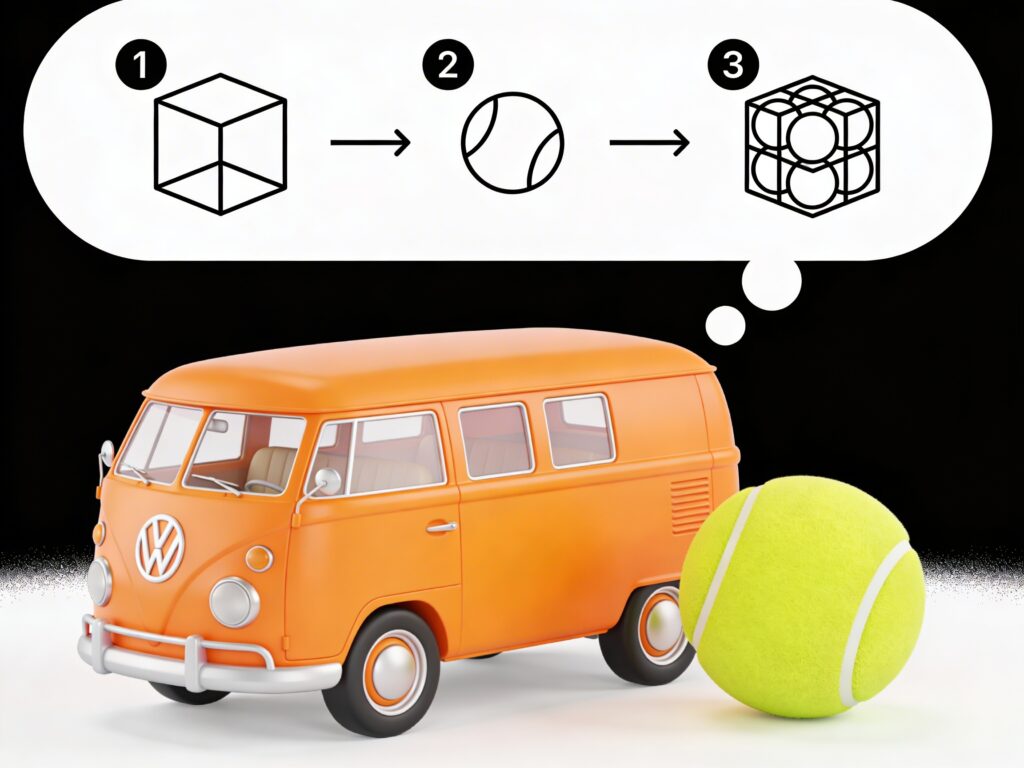
Auf die Frage „Wie viele Tennisbälle passen in einen Kleinbus?” antwortet ein klassisches Sprachmodell spontan mit einer Schätzung. Ein Reasoning-Modell hingegen zeigt seine Gedankenkette. Dieser „sichtbare Rechenweg” erlaubt es, Fehler nachzuvollziehen und zu korrigieren.
Für Interessierte: Die Antwort lautet ca. 43.000
Wie KI „lernt”, sich zu korrigieren
Technisch basiert diese Fähigkeit unter anderem auf Reinforcement Learning – einem Lernverfahren, bei dem das Modell durch Belohnungen trainiert wird: Es erhält positive Signale, wenn es eigene Fehler erkennt und korrigiert, wodurch es lernt, bessere Strategien zu entwickeln.
Diese „Belohnungen” sind keine monetären Anreize, sondern numerische Bewertungen im Trainingsprozess. Wichtig: Dieser iterative Prozess – tausende Male wiederholt während des Modell-Trainings vor der Veröffentlichung durch die Entwickler – trainiert das Modell, selbstständig vielversprechende Lösungswege zu identifizieren, ohne dass Menschen jeden einzelnen Schritt vorgeben müssen.
Hinzu kommt Test-Time Compute: Das Modell setzt nicht nur beim Training, sondern auch beim Antworten mehr Rechenleistung ein – es kann buchstäblich „länger nachdenken”.
Das Halluzinations-Paradox
Je komplexer das Reasoning, desto selbstbewusster werden die Modelle – was paradoxerweise dazu führt, dass sie bei unscharfen Fragen häufiger falsche Informationen als Fakten präsentieren, sogenannte Halluzinationen.
Reasoning-Modelle sind trainiert, niemals „Ich weiß es nicht” zu sagen. Stattdessen generieren sie selbstbewusste, detaillierte Antworten – selbst wenn die Datenlage dünn ist. Dies ist ein bewusster Trade-off: Mehr Problemlösungskraft erfordert mehr Risikobereitschaft.
Wann nutzen, wann nicht? Die Antwort hängt von der Überprüfbarkeit ab. Bei klar definierten Problemen – mathematische Beweise, Codeanalyse, Logikrätsel – sind die Modelle exzellent. Die Antworten lassen sich verifizieren: Funktioniert der Code? Stimmt die Rechnung?
Bei offenen, subjektiven Fragen hingegen steigt das Risiko deutlich. Ebenso problematisch sind zeitkritische Entscheidungen ohne Überprüfungsmöglichkeit: Medizinische Notfälle oder rechtliche Schritte sollten nie ausschließlich auf KI-Ratschlägen basieren.
Praxisnah für 60+: Drei Einsatzfelder
Drei aktuelle Modelle im Überblick
| Modell | Typische Stärke | Typische Grenze | Wofür sinnvoll |
| Gemini 3 Deep Think | Multimodale Langkontext-Analyse | Visuelles Reasoning schwächer als Konkurrenz | Längere Materialien, gemischte Formate (Text/Bild/Video) |
| Claude Opus 4.5 | Logik, Programmierung, Fachtextanalyse mit hoher Transparenz | Mehrsprachigkeit etwas schwächer | Technische Präzision, sensible Aufgaben, wissenschaftliche Literaturrecherche |
| OpenAI o3 | Sehr stark bei strukturierten Problemen | Offene Fragen riskanter, Reasoning teils intransparent | Mathematik/Logik mit guter Prüfbarkeit |
So machen Sie die KI sicherer: Methoden & Zukunft
Wie lässt sich das Risiko von Fehlern reduzieren? Hier helfen bereits heute drei Strategien, die auch die zukünftige Entwicklung prägen werden:
- Fakten-Check in Echtzeit (RAG): Wenn es um harte Fakten geht (z. B. medizinische Studien, aktuelle Gesetze), sollten Sie Modelle nutzen, die „Retrieval-Augmented Generation” (RAG) beherrschen. Das bedeutet einfach: Die KI sucht erst in vertrauenswürdigen Quellen nach, bevor sie antwortet – statt nur aus ihrem Gedächtnis zu plaudern.
- Die „Chain-of-Verification” (CoVe): Eine spannende Methode, die Forscher (u. a. von Meta) entwickelt haben: Das Modell generiert erst eine Antwort und zerlegt sie dann selbst kritisch in überprüfbare Häppchen, sucht nach Widersprüchen und korrigiert sich. Es führt quasi ein internes „Peer-Review” durch. Tests zeigen, dass dies Halluzinationen deutlich senken kann.
- Unsicherheit erzwingen (Prompting): Fordern Sie die KI heraus! Statt „Erkläre mir X”, fragen Sie lieber: „Wie sicher bist du dir auf einer Skala von 0 bis 100? Welche Annahmen hast du getroffen? Wo könnten Widersprüche liegen?” Das zwingt das Modell, seine „Selbstüberschätzung” offenzulegen.
Ausblick: Wir werden zunehmend hybride Systeme sehen, die Reasoning (Denken), RAG (Recherchieren) und Verification (Prüfen) automatisch kombinieren. Bis dahin bleibt der wichtigste Kontrollmechanismus: Ihr eigener kritischer Blick.
Fazit
Wenn Sie Reasoning-KI nutzen: Stellen Sie Fragen so, dass Sie die Antwort prüfen können – und bleiben Sie besonders kritisch, wenn die KI Ihnen genau das sagt, was Sie hören möchten.
Mich interessiert: Wo hat Ihnen KI schon einmal wirklich geholfen, klarer zu denken – und wo haben Sie gemerkt, dass sie „zu sicher” klingt? Schreiben Sie Ihre Erfahrungen und Ihre offenen Fragen gern in die Kommentare.
Demnächst: In den nächsten Beiträgen schauen wir uns „LLM-Modelle im Überblick”, und „Benchmarks verstehen” an.