
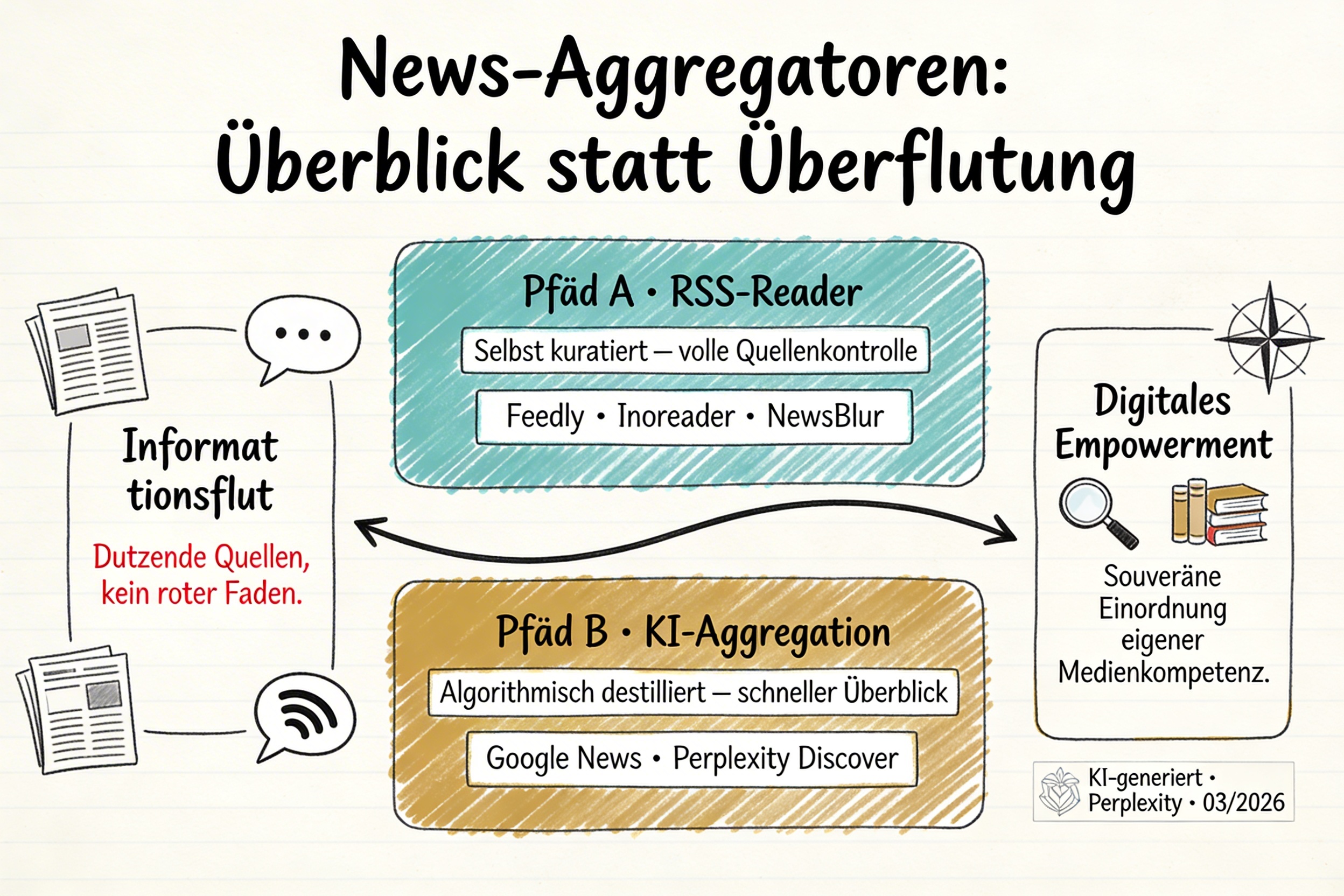
Zu viel Information ist auch keine Information. Wer täglich dutzende Quellen im Blick behalten will, verliert sich schnell im Rauschen. News-Aggregatoren versprechen Ordnung — doch das Angebot reicht heute von einfachem RSS bis zu KI-gestützter Zusammenfassung. Welcher Dienst wirklich nützt, hängt von Anspruch, Nutzungsweise und Risikobereitschaft ab.
Transparenz
Text und Bild(er) mit KI-Unterstützung erarbeitet.
Was ist ein News-Aggregator?
Ein News-Aggregator ist ein Dienst, der Inhalte aus mehreren Quellen an einem einzigen Ort bündelt. Die technische Grundlage ist das RSS-Format (Really Simple Syndication, zu Deutsch: sehr einfache Verbreitung): Websites stellen ihre Inhalte in einem standardisierten Format bereit, das Aggregatoren automatisch abrufen — ohne dass Lesende jede Seite einzeln aufrufen müssen.
RSS wurde Ende der 1990er Jahre entwickelt; die erste öffentliche Version erschien 1999. Warum ist das Prinzip heute wieder im Gespräch? Weil ein neuer Layer darüber gelegt wurde: Künstliche Intelligenz. KI-gestützte Dienste lesen nicht nur Feeds zusammen, sondern kuratieren, gewichten und fassen Inhalte zusammen — im Extremfall in einem einzigen Absatz. Das klingt verlockend, braucht aber Begleitung: Wer bestimmt, was relevant ist? Was geht verloren? Und was steht tatsächlich hinter einer Zusammenfassung?
Dieser Beitrag vergleicht klassische RSS-Reader mit KI-gestützten Aggregatoren, beleuchtet Paywall- und Datenschutzfragen — und zeigt Möglichkeiten zum Empowerment der eigenen Medienkompetenz.
Klassische Aggregatoren: Kontrolle im Abo-Modell
Bei klassischen RSS-Readern liegt die Kuratierung vollständig bei den Nutzenden. Wer Quellen auswählt, Ordner anlegt und Stichworte definiert, trifft bereits eine inhaltliche Entscheidung, bevor irgendein Algorithmus ins Spiel kommt. Was ein Verlag freigibt, erscheint im Feed. Bezahlpflichtige Inhalte bleiben hinter der Paywall des Verlags: Der Reader zeigt in der Regel Teaser oder Zusammenfassungen, aber keinen Volltext.
Feedly gehört zu den bekanntesten Vertretern. Die Oberfläche ist übersichtlich, der Einstieg gelingt schnell. Der kostenlose Plan erlaubt eine begrenzte Anzahl von Quellen und einfache Ausblend-Filter (sogenannte Mute Filters); das vollständige Stichwort-Monitoring mit automatischen Keyword-Alerts ist dem Pro-Plan vorbehalten, der ab etwa 8 Euro pro Monat verfügbar ist. Im Bezahlmodell ist zusätzlich ein KI-Assistent namens „Leo” integriert, der Artikel nach selbst definierten Themen gewichtet und filtert. Die Server stehen in den USA. Für wen? Feedly eignet sich gut für den Einstieg: wenige Quellen, übersichtliche Ordnerstruktur, mobil gut nutzbar — solange kein aktives Stichwort-Monitoring benötigt wird.
Inoreader richtet sich an Nutzende, die ihre Informationsarchitektur feiner steuern wollen. Der wesentliche Unterschied liegt in der Tiefe der Kontrolle: Der kostenlose Plan erlaubt bis zu 150 Quellen; dazu kommen regelbasierte Filter, mit denen sich Artikel nach Stichwort, Autor oder Quelle automatisch sortieren, markieren oder ausblenden lassen. Auch Suchabo-Funktionen — also automatisches Monitoring bestimmter Begriffe — sind bereits im kostenlosen Plan möglich. Der Pro-Plan kostet etwa 7,50 US-Dollar pro Monat. Der Serverstandort für europäische Nutzende ist nicht eindeutig dokumentiert; ein Blick in die Datenschutzerklärung wird empfohlen. Für wen? Inoreader ist die erste Wahl für alle, die thematisch präzise steuern und sich nicht auf algorithmisches Gewichten verlassen wollen.
Flipboard nimmt eine Sonderstellung ein. Die App präsentiert Inhalte im Magazin-Layout und wirkt optisch ansprechend. Dahinter steckt jedoch ein anderes Modell: Flipboard ist werbefinanziert, kuratiert algorithmisch und bewegt sich in seiner Logik näher an sozialen Netzwerken als an klassischem RSS. Der Algorithmus bestimmt die Feed-Zusammensetzung mit, ohne dass dies transparent wäre. Für wen? Nutzende, denen optische Aufbereitung wichtiger ist als Quellentransparenz und Steuerbarkeit.
NewsBlur ist eine Open-Source-Alternative mit gutem Datenschutzprofil. Der Dienst lässt sich als Cloud-Version nutzen oder auf einem eigenen Server betreiben (Self-Hosting via Docker; technische Dokumentation und Quellcode sind öffentlich auf GitHub verfügbar). Ein sogenannter Intelligence Trainer ermöglicht es, Inhalte nach Autor, Stichwort oder Thema zu trainieren — ähnlich einem lernenden Filter. Der kostenlose Plan umfasst bis zu 64 Quellen. Für wen? Die Cloud-Version ist ohne technisches Vorwissen zugänglich. Wer vollständige Souveränität sucht, findet im Self-Hosting die konsequenteste Lösung.
Kurz erklärt — Self-Hosting: Einen Dienst selbst betreiben bedeutet, die entsprechende Software auf einem eigenen Server zu installieren. Daten bleiben vollständig unter eigener Kontrolle; dafür ist technisches Grundwissen erforderlich.
KI-gestützte Aggregation: Überblick oder Blackbox?
KI-gestützte Aggregatoren gehen einen Schritt weiter als klassische RSS-Reader. Sie entscheiden, was angezeigt wird — und fassen Inhalte teils in eigene Worte.
Google News ist kostenlos, liefert tagesaktuelle Inhalte und ist ohne Einrichtungsaufwand nutzbar. Eine aktive Steuerung ist möglich: Themen und Quellen lassen sich manuell folgen, personalisierte Empfehlungen können ein- und ausgeschaltet werden. Die algorithmische Grundlogik bleibt jedoch nicht offengelegt. Die Bundeszentrale für politische Bildung folgerte in einem im März 2024 veröffentlichten Beitrag, dass algorithmisch kuratierte Feeds das Risiko einer Filterblase erhöhen können — empirische Befunde dazu sind allerdings uneinheitlich.
Perplexity Discover (der „Entdecken”-Button rechts oben in der deutschsprachigen App) ist ein eigener Bereich innerhalb der Perplexity-App, der automatisch kuratierte Trendthemen und Nachrichtenzusammenfassungen anzeigt. Die verwendeten Quellen werden als klickbare Links ausgewiesen — das unterscheidet Perplexity von Google News, wo die Gewichtungslogik vollständig im Verborgenen bleibt. Die interne Auswahllogik von Perplexity ist jedoch ebenfalls nicht dokumentiert. Als Large Language Model (LLM) kann Perplexity fehlerhafte Ergebnisse produzieren; ein kritischer Blick auf jede Zusammenfassung bleibt unverzichtbar.
Das Paywall-Problem: Was die KI wirklich liest
Wenn eine KI-Zusammenfassung über einen Artikel berichtet, der hinter einer Bezahlschranke liegt, sind drei Szenarien möglich:
- Szenario 1 — Korrekt: Die KI fasst frei zugängliche Inhalte korrekt zusammen. Quellen sind transparent und nachvollziehbar.
- Szenario 2 — Fast korrekt: Die KI rekonstruiert Bezahlinhalte aus Sekundärquellen — also aus anderen Berichten über denselben Artikel. Nuancen gehen verloren. Die Zusammenfassung wirkt stimmig, kann aber unvollständig oder leicht verzerrt sein.
- Szenario 3 — Fehlleitend: Die KI füllt Lücken mit plausibel klingenden, aber falschen Details — das bekannte Halluzinations-Problem, das besonders dann greift, wenn man es am wenigsten bemerkt.
Das strukturelle Problem: Beim Lesen weiß man nicht, welches Szenario gerade zutrifft. Die Chicago Tribune hat Perplexity im Dezember 2025 in New York verklagt und wirft dem Unternehmen vor, Bezahlinhalte über sein RAG-System (Retrieval Augmented Generation — eine Methode, bei der aktuelle Inhalte aus dem Netz in KI-Antworten eingespeist werden) verarbeitet und über seinen Browser „Comet” Paywalls aktiv umgangen zu haben. Ähnliche Rechtsstreitigkeiten gibt es gegenüber Google: Mehrere deutsche Medienhäuser haben 2025 beim Landgericht Hamburg Klage gegen Googles KI-Übersichten eingereicht und berufen sich dabei auf das deutsche Leistungsschutzrecht. Beide Verfahren sind noch offen.
Was bedeutet das praktisch? Bei wichtigen Themen lohnt es sich, die in einer KI-Zusammenfassung genannten Quellen direkt aufzurufen. Quellenangaben bei Perplexity lassen sich anklicken und prüfen — konsequent nutzen. Bei Google News fehlt diese Quellenangabe in der KI-Übersicht; ein direkter Klick auf den Originalartikel ist der einzig verlässliche Weg zur Verifizierung.
Dienste im Vergleich
| Dienst | Kosten (März 2026) | Typischer Workflow | Relevanz & Aktualität | Lernkurve | KI-Anteil | Datenschutzprofil | DSGVO | Open Source |
|---|---|---|---|---|---|---|---|---|
| Feedly | Free (begrenzt) / ab ~8 €/Mt. | Quellen → Ordner → Artikelliste → optional KI-Filter „Leo” | Gut, selbst kuratiert | Niedrig | Optional (Bezahl) | US-Server, begrenztes Profil | Eingeschränkt | Nein |
| Inoreader | Free (150 Quellen) / ab ~7 €/Mt. | Quellen + Stichwort-Abos → regelbasierte Filter → Inbox + Volltextsuche | Sehr gut, feingranular steuerbar | Mittel | Gering | EU-Status unklar — prüfen | Prüfen | Nein |
| Kostenlos (werbefinanziert) | Themen folgen → algorithmisch kuratierter Magazin-Feed | Mittel, algorithmisch | Sehr niedrig | Hoch | Werbeprofil, intransparent | Fraglich | Nein | |
| NewsBlur | Free (64 Quellen) / Self-Host | Quellen → Intelligence Trainer → River of News oder Story-Ansicht | Gut, trainierbar | Mittel–Hoch | Gering | Selbst kontrollierbar | Ja (Self-Host) | Ja |
| Google News | Kostenlos | Themen/Quellen folgen → Algorithmus kuratiert Tagesseiten | Sehr hoch, sehr aktuell | Sehr niedrig | Sehr hoch | Google-Ökosystem, tiefes Profil | Fraglich | Nein |
| Perplexity Discover | Free / Abo | Discover-Bereich öffnen → KI liefert kuratierte Trendthemen → Quellen anklickbar | Hoch, KI-destilliert | Sehr niedrig | Sehr hoch | US-basiert, intransparent | Eingeschränkt | Nein |
Datenschutz: Was das Leseverhalten verrät
Bezogen auf News-Aggregatoren stellt sich eine doppelte Datenschutzfrage: Wie tief ist das Profil, das entsteht — und wer hat ein Interesse daran?
Das Interesse ist handfest: Präzise Verhaltensdaten lassen personalisierte Werbung zu, können für politische Kampagnen genutzt werden und liegen auch im Interesse einiger Regierungen. Ein Leseprofil, das politische Tendenzen, Gesundheitsthemen oder weltanschauliche Orientierungen erkennen lässt, ist entsprechend wertvoll.
Zwei Dimensionen sind dabei zu unterscheiden. Auch klassische Cloud-RSS-Reader ohne KI-Personalisierung speichern Nutzungsdaten — welche Quellen abonniert sind, welche Artikel als gelesen markiert wurden. Das entstehende Profil ist begrenzt: Es zeigt, welche Quellen jemand abonniert, nicht wie gelesen wird. KI-gestützte Dienste benötigen tiefere Verhaltenssignale (welche Artikel vollständig gelesen, wie lange, welche angeklickt wurden), um zu personalisieren — das resultierende Profil ist entsprechend aussagekräftiger.
Feedly, Google News und Perplexity betreiben ihre Infrastruktur unter US-Recht — das bedeutet eingeschränkte europäische Durchsetzungsmöglichkeiten bei Datenschutzverstößen. Inoreaders EU-Serverstandort ist nicht abschließend verifiziert. NewsBlur im Self-Hosting eliminiert den Datentransfer zu Drittanbietern vollständig.
Die Abwägung ist eine persönliche Entscheidung. Wer Google bereits für Suche, Mail und Kalender nutzt, erweitert das bestehende Profil kaum merklich. Wer den Abfluss von Informationen über das persönliche Leseverhalten gezielt begrenzen möchte, findet mit NewsBlur und — bei verifiziertem EU-Standort — mit Inoreader konkrete Alternativen.
Eigenes Prompting: Medienkompetenz aktiv stärken
Wer jahrzehntelang Zeitung gelesen, Quellen abgewogen und Berichte eingeordnet hat, bringt eine Kompetenz mit, die kein Algorithmus repliziert: die Fähigkeit zu urteilen, was eine Quelle wert ist, welche Perspektive fehlt, welche Aussage zu hinterfragen ist. Diese Stärke lässt sich direkt in den Umgang mit News-Aggregatoren übersetzen.
Schritt 1: Bewusste Quellenwahl als erster Filter
Das Grundprinzip gilt für alle Aggregatoren — von Feedly bis Google News: Wer entscheidet, welche Quellen abonniert und welche Stichworte gesetzt werden, übernimmt die Kontrolle, die sonst der Algorithmus hat. Statt einem Dienst die vollständige Kuratierung zu überlassen, entsteht so eine persönliche Informationsarchitektur. Das klingt selbstverständlich — wird aber bei der Einrichtung eines neuen Tools oft übersprungen. Welche Quellen liefern Perspektiven jenseits des eigenen Ausschnitts?
Schritt 2: Das Werkzeug hinter dem Werkzeug
Wer noch einen Schritt weitergeht, verlässt die Logik des passiven Konsums ganz. Der Ansatz: nicht mehr nach Stichwörtern in der Gesamtheit aller Quellen suchen, sondern gezielt in einem persönlichen Artikelarchiv arbeiten oder manuell aus den Feeds vorsteuern.
Zotero eignet sich hier als ein mögliches Helferlein. Das freie Literaturverwaltungsprogramm lässt sich weit über akademische Literatur hinaus einsetzen: Feeds, Artikel, Webseiten und PDFs lassen sich über den Browser-Connector direkt in thematischen Sammlungen ablegen. Es entsteht ein persönliches Archiv, das die eigene Urteilskraft und die eigenen Interessen klar widerspiegelt — eine bewusste Sammlung relevanter Quellen, kein algorithmisch zusammengestellter Feed. → Mehr dazu im Zotero-Beitrag des Blogs.
Im nächsten Schritt wird dieses Archiv zur Grundlage für gezielte KI-Abfragen. Dafür eignen sich Werkzeuge, die ausschließlich auf Basis der hochgeladenen Quellen antworten — ohne eigenständig im Netz zu suchen. NotebookLM von Google funktioniert nach diesem Prinzip: Hochgeladene Quellen bilden den abgeschlossenen Arbeitsraum, das System antwortet ausschließlich auf dieser Basis. Ähnlich funktionieren Upload-Funktionen anderer KI-Dienste wie ChatGPT oder Claude — der entscheidende Schritt ist dabei immer der gleiche: die eigene Quellenauswahl vor der KI-Abfrage.
Für Nutzende, die auch diesen Diensten gegenüber datenschutzkritisch eingestellt sind, bietet Ollama eine lokale Alternative. Ollama ist eine frei verfügbare Anwendung, die sich wie normale Software installieren lässt und Sprachmodelle direkt auf dem eigenen Rechner betreibt — ohne Internetzugang, ohne Datentransfer zu Dritten. Technische Voraussetzung: wer Software installieren und grundlegende Einstellungen vornehmen kann, kommt damit zurecht.
Grenzen und offene Fragen
Kein Aggregator ersetzt eigene Quellenkritik. Auch ein selbst kuratierter RSS-Feed bildet nur ab, was die ausgewählten Verlage berichten. Welche Themen gar nicht erscheinen, lässt sich nur durch aktives Erweitern der Quellenauswahl feststellen.
Dieser Beitrag basiert auf öffentlichen Produktseiten, Datenschutzerklärungen der Anbieter, einem Heise-Vergleichstest (Januar 2025) sowie Medienberichten zu rechtlichen Entwicklungen rund um KI-Aggregatoren. Recherche-Zeitraum: Februar–März 2026.
Offene Punkte: Der EU-Serverstandort von Inoreader konnte zum Redaktionsschluss (10.03.2026) nicht abschließend verifiziert werden. Die Rechtslage rund um KI-Aggregatoren und Urheberrecht befindet sich in Bewegung — aktuelle Urteile in den laufenden Verfahren (Chicago Tribune vs. Perplexity; deutsche Verlage vs. Google) können die Situation verändern.
Quellenverzeichnis
- Heise Online: Acht RSS-Reader im Vergleich, Januar 2025
- meedia.de: „Chicago Tribune wirft Perplexity Umgehung der Paywall vor”, Dezember 2025
- The Decoder: „Perplexity kopiert bei News-Seiten”, Juni 2024
- schieb.de: „KI-Übersichten bei Google: Warum Verlage jetzt klagen”, Juli 2025
- Bundeszentrale für politische Bildung: „Mythos Filterblase”, Februar 2024
- tagesschau.de Faktenfinder: Filterblasen
- Inoreader, NewsBlur, Feedly, Google, Perplexity: Anbieter-Datenschutzerklärungen (Stand März 2026)